dataset包简介¶
dataset包主要包含了气象数据文件读写的功能。addfile是最主要的读取数据文件的函数,支持NetCDF、GRIB、HDF、GrADS等常用气象数据 格式,该函数返回值是多维数据文件(DimDataFile)的对象,文件对象里包含了数据维、全局属性、变量(包括变量类型、变量维、变量属性) 的信息。下面的例子中用addfile函数打开MeteoInfo里的GrADS格式的示例数据文件model.ctl,获得文件对象变量f,在Console中输入变量名 f回车显示该变量的信息:数据文件中共有5个维(X、Y、Z、T、Z_5),8个变量。例如变量T的数据类型是浮点型(float),变量有4个维 (依次是T、Z、Y、X,分别代表时间、高度、维度、经度),变量有一个属性“T: description = Temperature”说明该变量表示的是温度。 而PS变量是地面气压,只有三个维(T、Y、X)。
>>> fn = os.path.join(migl.get_sample_folder(), 'GrADS', 'model.ctl')
>>> f = addfile(fn)
>>> f
File Name: D:/MyProgram/Distribution/Java/MeteoInfo/MeteoInfo\sample\GrADS\model.ctl
Dimensions: 5
X = 72;
Y = 46;
Z = 7;
T = 5;
Z_5 = 5;
X Dimension: Xmin = 0.0; Xmax = 355.0; Xsize = 72; Xdelta = 5.0
Y Dimension: Ymin = -90.0; Ymax = 90.0; Ysize = 46; Ydelta = 4.0
Global Attributes:
: data_format = "GrADS binary"
: fill_value = -2.56E33
: title = "5 Days of Sample Model Output"
Variations: 8
float PS(T,Y,X);
PS: description = "Surface"
float U(T,Z,Y,X);
U: description = "U"
float V(T,Z,Y,X);
V: description = "V"
float Z(T,Z,Y,X);
Z: description = "Geopotential"
float T(T,Z,Y,X);
T: description = "Temperature"
float Q(T,Z_5,Y,X);
Q: description = "Specific"
float TS(T,Y,X);
TS: description = "Surface"
float P(T,Y,X);
P: description = "Precipitation"
还有一些读取特定格式数据文件的函数如:
addfile_grads – 读取GrADS格式数据文件
addfile_nc – 读取NetCDF格式数据文件
addfile_grib – 读取GRIB格式数据文件
addfile_arl – 读取ARL格式数据文件
addfile_micaps – 读取MICAPS格式数据文件
addfile_surfer – 读取Surfer文本格点数据文件
addfile_mm5 – 读取MM5模式输出数据文件
addfile_lonlat – 读取有经纬度列的表格文本数据文件
addfile_hytraj –读取HYSPLIT模式输出气团轨迹数据文件
addfile_hyconc – 读取HYSPLIT模式输出浓度数据文件
addfile_geotiff – 读取Geotiff格式数据文件
addfile_bil – 读取BIL格式数据文件
addfile_awx – 读取AWX格式数据文件
addfile_ascii_grid – 读取ESRI格点文本数据文件
利用读取数据文件的函数获得文件对象后,可以从文件对象中利用变量名获取多维变量对象(DimVariable),例如f[‘PS’]能够从文件对象f 中获取“PS”变量对象(地面气压)。
>>> var = f['PS']
>>> var
float PS(T,Y,X):
PS: description = "Surface"
从变量对象中根据维可以切片获取多维数组。例如从var变量对象中获取第一个时次的地面气压二维(Y、X)数组,可以将第一维(T)固定为0, 第二维(Y)和第三维(X)设为“:”表示全部取值。
>>> ps = var[0,:,:]
>>> ps
array([[670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857, 670.15857]
[689.02344, 681.99927, 675.3096, 668.8875, 663.1344, 657.78265, 652.89923, 648.5509, 645.2061, 642.93164, 641.7275, 641.5937, 642.4633, 644.13574, 646.4102, 648.95233, 651.82886, 654.50476, 656.9799, 659.0537, 660.8599, 662.1979, 663.0675, 663.66956, 664.1379, 664.7399, 665.8772, 667.81714, 671.0282, 675.77783, 682.6682, 691.0303, 700.931, 712.1028, 724.88, 737.5904, 749.89935, 761.53937, 772.24286, 781.6084, 788.3649, 792.91394, 795.12146, 794.6532, 791.6429, 786.6925, 780.27045, 772.8449, 764.9511, 758.1277, 752.5752, 748.829, 747.4242, 748.6283, 752.10693, 757.4587, 764.2153, 771.57385, 777.9291, 782.6787, 785.2208, 785.02014, 781.8091, 776.0559, 768.1621, 758.46216, 747.2904, 736.3862, 725.6159, 715.3807, 705.4131, 696.78345]
[679.1896, 672.9682, 666.8137, 659.3882, 650.82544, 641.1254, 630.89026, 620.58813, 611.9585, 605.6033, 601.5226, 599.78326, 599.91705, 601.0543, 602.52606, 604.1985, 606.60675, 610.2192, 615.3033, 622.1268, 630.6895, 640.6571, 650.62476, 660.2579, 668.9544, 676.8482, 683.6717, 691.0303, 701.0648, 716.31726, 739.798, 769.7008, 805.69116, 844.7588, 884.5623, 917.2079, 941.49133, 958.1487, 968.25, 972.8659, 972.1969, 966.0425, 953.73346, 933.7983, 909.0465, 882.22095, 855.3285, 829.70703, 806.4939, 788.03046, 773.44696, 763.94763, 761.6063, 769.1656, 786.8263, 813.65186, ...]])
后面全部取值的维也可以省略,ps = var[0]和上面的结果是一样的。也可以从文件对象中直接获取每个变量的多维数组。
>>> ps = f['PS'][0]
>>> ps.shape
(46, 72)
从数据文件中以上述方式读取的多维数组均为DimArray对象,也就是包含维的标注信息,方便后续相关数据分析。在读取数组维的设置还可以根据 维的值来切片,比如要从温度变量中读取第一个时次、高度从1000到100百帕、维度从-90到90、经度为270的数组,可以用下面的语句,注意维 的值范围是字符串(有双引号或者单引号)。
>>> t = f['T'][0,'1000:100','-90:90','270']
>>> t.shape
(7, 46)
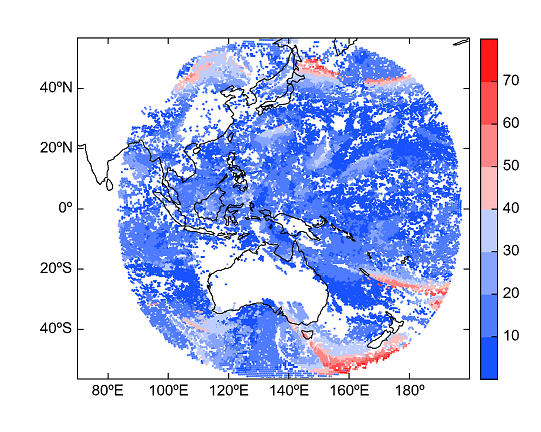
addfile函数也可以读取BUFR文件,但从BUFR文件中读取数组比较特殊。BUFR文件中只包含一个变量obs,是Sequence类型,包含了一些成员 (member),成员的名称可以用obs变量对象的get_members方法获取,可以用obs的member_array方法读取成员数组。需要注意的是在 addfile函数中将keepopen参数设为True,所有数据读取完毕后用数据文件对象的close方法关闭文件。
fn = 'D:/Temp/bufr/aaaa.bufr'
f = addfile(fn, keepopen=True)
obs = f['obs']
print(obs.varnames)
lon = obs['Longitude_high_accuracy'][:]
lon[lon<0] = lon + 360
lat = obs['Latitude_high_accuracy'][:]
ws = obs['Wind_speed'][:]
f.close()
geoshow('country')
scatter(lon, lat, ws, edgecolor=None, size=2, cmap='BlueRed', zorder=0)
xlim(70, 200)
colorbar()
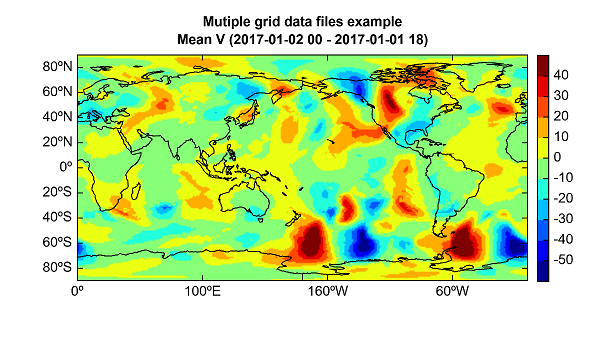
对于多个包含相同维和变量信息,且时间相邻接的数据文件,可以用addfiles函数一次性读取,相当与将多个文件当作一个时间序列更长的文件来 处理。
datadir = 'D:/Temp/grib'
st = datetime.datetime(2017,1,1,0)
et = datetime.datetime(2017,1,1,18)
fns = []
while st <= et:
fn = os.path.join(datadir, 'fnl_' + st.strftime('%Y%m%d_%H') + \
'_00.grib2')
print fn
fns.append(fn)
st = st + datetime.timedelta(hours=6)
fs = addfiles(fns)
v = fs['v-component_of_wind_tropopause']
data = v[:,::-1,:]
data = mean(data, axis=0)
geoshow('continent')
layer = imshow(data, interpolation='bilinear')
colorbar(layer)
xlim(0, 360)
ylim(-90, 90)
title('Mutiple grid data files example\nMean V (' + st.strftime('%Y-%m-%d %H') + ' - ' + \
et.strftime('%Y-%m-%d %H') + ')')